October 6, 2025
Auto-Healing Based on Observability Data: Closing the Loop Between Detection and Recovery

By Priyank Dhami
Improwised Technologies Pvt. Ltd.
In the complex architectures of modern systems, the ability to autonomously detect and recover from failures is no longer a luxury but a necessity. The increasing interdependencies between services, microservices, and infrastructure components necessitate mechanisms that not only detect anomalies but also trigger recovery actions to restore normal operation. Auto-healing, powered by observability data, provides such a mechanism, enabling systems to respond to issues without manual intervention.
This blog explores the technical implementation of auto-healing mechanisms that rely on observability data, focusing on the critical components, methodologies, and challenges that engineers must address. The objective is to bridge the gap between detection and recovery, enabling systems to self-heal efficiently in production environments.
Understanding Observability and Its Role
Observability refers to the capacity to understand the internal state of a system by examining the external outputs, such as logs, metrics, and traces. These outputs provide insights into the behavior of various system components, allowing engineers to detect failures, performance degradation, or unexpected behavior. Observability data becomes the foundation upon which auto-healing mechanisms are built.
In traditional systems, observability often served as a diagnostic tool, assisting engineers in pinpointing issues during post-mortem analyses. However, with the rise of distributed systems and microservices, manual intervention for failure recovery becomes impractical. Instead, the combination of real-time observability data and automated recovery mechanisms can significantly reduce mean time to recovery (MTTR) and improve system reliability.
The Components of Auto-Healing Systems
An auto-healing system involves several distinct but interconnected components that work together to detect, diagnose, and recover from failures. These components include monitoring, detection algorithms, remediation actions, and feedback loops.
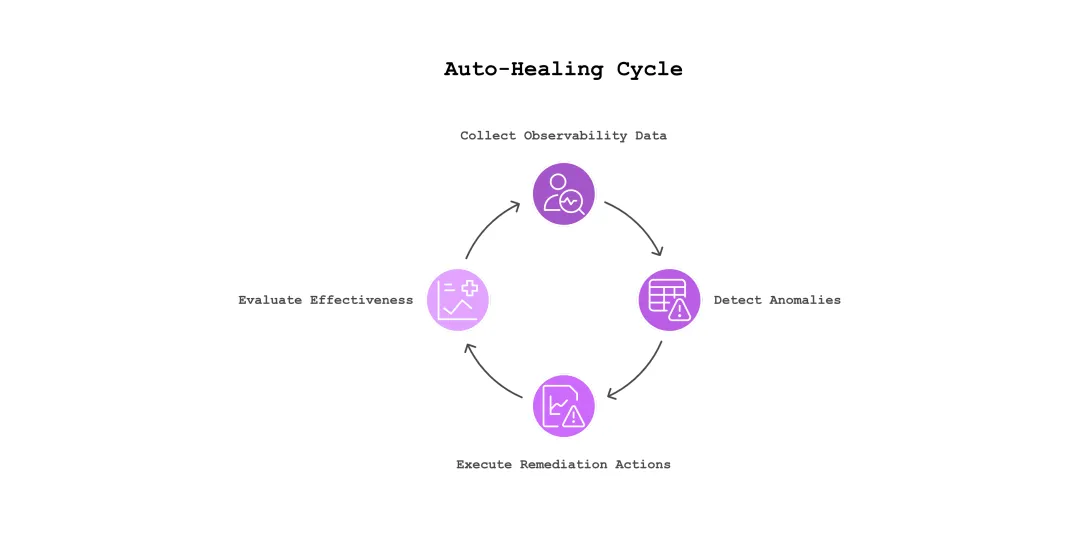
1. Monitoring and Data Collection
The first step in any auto-healing mechanism is the collection of observability data. This data typically comes from three primary sources:
-
Metrics: Quantitative data, such as resource utilization (CPU, memory, disk I/O) or application performance (response times, throughput), that indicate the health of system components.
-
Logs: Text-based records that provide detailed information about events, errors, or unexpected conditions within the system. Logs are crucial for understanding the context of failures.
-
Traces: Distributed traces that capture the flow of requests across services, providing a fine-grained view of system behavior and latency bottlenecks.
These data sources form the backbone of the monitoring infrastructure, enabling systems to continuously observe and track key performance indicators (KPIs).
2. Detection Algorithms
Once the monitoring system is in place, the next step is to implement detection algorithms. These algorithms process the observability data to identify anomalies, failures, or conditions that warrant recovery actions. There are several approaches to anomaly detection, including:
-
Threshold-based Detection: A simple yet effective approach where predefined thresholds for key metrics (e.g., CPU usage > 80%) trigger alerts or actions when exceeded.
-
Statistical Anomaly Detection: Methods like moving averages, standard deviation, and percentiles that detect deviations from normal behavior based on historical data.
-
Machine Learning Models: Advanced models such as clustering, classification, or neural networks can be trained to identify complex patterns in large datasets and predict failures before they occur.
Regardless of the detection method used, the goal is to accurately identify failure conditions promptly without causing unnecessary alarms (false positives) or missing critical issues (false negatives).
3. Remediation Actions
Once a failure or anomaly is detected, the system must take corrective action. Remediation can range from simple tasks like restarting a failed service to more complex procedures such as redistributing load across available resources or applying configuration changes.
The types of remediation actions depend on the nature of the issue and the system architecture. Some common auto-healing actions include:
-
Restarting Components: If a service crashes or hangs, restarting it might be sufficient to restore normal operation.
-
Scaling Services: If resource utilization exceeds a certain threshold, scaling the service up or down can alleviate the load and prevent degradation.
-
Service Failover: In cases of server or region failure, routing traffic to a healthy replica or backup can ensure availability.
-
Configuration Rollback: In situations where a misconfiguration causes issues, rolling back to a previous known good configuration can resolve the problem.
Automating these actions based on the observability data enables the system to self-heal, eliminating the need for manual intervention.
4. Feedback Loops and Continuous Improvement
An important aspect of auto-healing is the feedback loop, which ensures that the system adapts over time based on new data. After an incident is detected and remediation is performed, the system should evaluate the effectiveness of the recovery action and adjust its detection algorithms or remediation strategies if necessary.
For example, if a false positive occurs (where an alert is triggered unnecessarily), the system should refine its thresholding or detection model to prevent similar alerts in the future. Similarly, if a remediation action does not fully resolve the issue, the system should initiate a more aggressive recovery plan.
Feedback loops are essential for ensuring that the auto-healing process becomes more efficient and accurate with each cycle.
Technical Challenges in Implementing Auto-Healing
While auto-healing systems offer significant benefits, their implementation comes with several challenges:
1. Data Overload
The volume of observability data generated in complex systems can be overwhelming. Without effective data processing and filtering mechanisms, noise in the data can obscure real problems, making it difficult to identify true issues. Engineers must design systems that can prioritize critical events while minimizing the impact of irrelevant data.
2. Identifying the Right Remediation Action
Not all failures have the same root cause, and not all remediation actions will work for every situation. For instance, restarting a service may resolve transient failures, but it may not address underlying issues like resource exhaustion or misconfiguration. Developing intelligent remediation strategies that adapt to different failure scenarios requires a deep understanding of the system’s architecture and failure modes.
3. Coordination in Distributed Systems
In microservices-based architectures, failures often span multiple components or services. An issue in one service may cascade to others, making it difficult to isolate and address the root cause. Auto-healing mechanisms must be able to identify whether the problem is isolated to a single component or whether a broader remediation effort is required across the system.
4. Managing Recovery Impact
While auto-healing actions can restore service availability, they can also have unintended side effects. For example, restarting a service might temporarily disrupt user experience, or failover to another instance could lead to increased latency. Ensuring that recovery actions are non-disruptive or minimally disruptive to end users is a key consideration in designing auto-healing systems.
Closing the Loop Between Detection and Recovery
The ultimate goal of auto-healing is to close the loop between detection and recovery. Systems must not only detect failures but also respond to them autonomously in real-time, minimizing the need for human intervention. This requires tight integration between monitoring, anomaly detection, and automated remediation. Furthermore, the system must continuously evaluate and refine its recovery processes through feedback loops to ensure it becomes more efficient over time.
One approach to closing this loop is to integrate machine learning models with observability data to predict failures before they occur. Predictive models can identify early warning signs and trigger preemptive recovery actions, such as scaling services or reallocating resources, before a failure causes significant disruption.
Consequences of Inadequate Auto-Healing Systems
If auto-healing mechanisms are not implemented effectively, several negative consequences can arise:
-
Increased Downtime: Manual intervention is often required to address failures, resulting in longer recovery times and increased system downtime.
-
Decreased System Reliability: Without the ability to recover automatically, systems may experience prolonged outages or degraded performance, undermining user trust and service availability.
-
Operational Overhead: Failure detection, diagnosis, and recovery may require significant engineering resources, which could otherwise be used for developing new features or optimizing the system.
-
Poor User Experience: Slow recovery times and service disruptions lead to poor user experiences, especially in high-availability environments where users expect immediate service restoration.
Conclusion
Auto-healing based on observability data is an essential component of modern systems, especially those built on microservices or distributed architectures. By automating failure detection and recovery, organizations can ensure higher availability, lower operational costs, and improved user experience. However, implementing such systems requires careful consideration of the technical challenges involved, including data overload, remediation strategy design, and coordination in distributed environments.
Failing to implement robust auto-healing mechanisms can lead to increased downtime, reduced system reliability, and higher operational costs. As systems grow more complex, the need for self-healing systems that can autonomously detect and recover from failures will only increase, making it imperative for organizations to adopt and refine these strategies to stay competitive.
Turn your observability data into autonomous recovery paths for modern systems. Contact our platform engineering experts to discuss how we can help you build an autonomous recovery mechanism tailored to your infrastructure’s requirements.
Written by
Priyank Dhami
Priyank Dhami is the Vice President of Global Business Development & Partnerships at Improwised Technologies. With strong expertise in platform engineering, open-source ecosystems, and solution architecture, he bridges the gap between technology and business to deliver impactful, client-centric solutions.

November 19, 2025
Unlocking Developer Potential: How Platform Engineering Transforms Developer Experience

By Shyam Kapdi
Improwised Technologies
Pvt. Ltd.

By Shyam Kapdi
Improwised Technologies
Pvt. Ltd.

November 14, 2025
How to Build a High-Impact Internal Developer Platform: Step-by-Step Blueprint, Tools, and Best Practices
By Shyam Kapdi
Improwised Technologies
Pvt. Ltd.
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.